Someone preparing a critique of a research article wanted to check the accuracy of the statistics in that article. They noted that in a group of 37 patients without the intervention, only one was successful in avoiding a certain type of risky behavior. In a group with counseling, 7 out of 44 avoided the risky behavior.
My first thought is that this risky behavior must be awfully fun if so many people indulge in it!
It’s nice to double check the statistics used in journal articles as there are often errors. One memorable one cited in this weblog is
The problem, unfortunately, is the the term “Chi-square test” is used in a variety of different contexts, as I allude to in an “Ask Professor Mean” question.
This person looked in SPSS and found a Chi-square test in the menus under ANALYZE | NON_PARAMETRIC TEST | CHI-SQUARE. Here’s the output that the program produced:
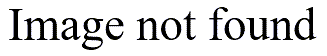 height=“135”}
height=“135”}
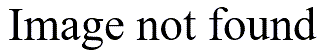
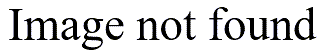
Unfortunately, this is the wrong test to use, because it examines whether the proportion who avoided the risky behavior was equal to the proportion who did not. This is a rather meaningless hypothesis, but when you click on the choices in any statistical software program, nowhere does the program warn you that this is a meaningless hypothesis.
Software programs have tried to build a level of intelligence into their programs so that users are steered toward the correct approaches with some success, and eventually we will see the day when computers can accurately choose from among competing statistical procedures without any human intervention. I will be long retired before that day happens, though, so I am not too worried about losing my job to a computer.
Here’s the correct analysis, by the way, using the CROSSTABS procedure.
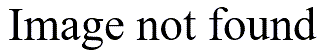
You could also get a similar result using logistic regression.
How do you know to use crosstabs for this particular application? It takes a bit of experience. One hint is that you have an exposure or treatment variable (did the patient get advice/counseling?) and an outcome variable (did they abstain from risky behavior). When you are trying to predict a categorical outcome, logistic regression is a good choice. I used crosstabs because the problem is simpler and the output is a bit easier to follow. But logistic regression would have been a fine choice as well.
By the way, I use the unusual coding “1-Yes” and “2-No” to control the order in which the columns and rows are displayed. By default, SPSS will alphabetize the rows and columns, and I wanted the NO category to appear after the YES category.
Related links on this web site: