I’m working on a microarray experiment of prenatal liver samples. When I was trying to normalize the data, I noticed that three of the arrays had rather unusual properties. When trying to normalize array 6287 versus the median array, for example, the R vs I plot looked like
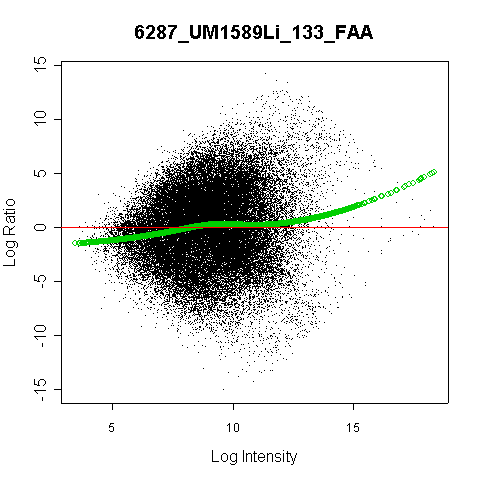
which was much more scattered than most of the other plots, such as 7446.
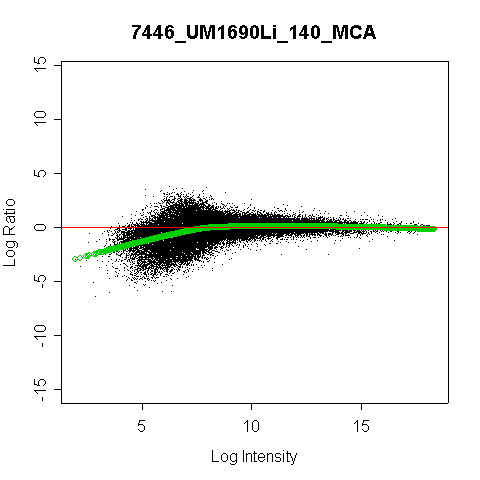
When I plotted pairs of arrays versus each other, it became even more apparent. Here is what 6287 versus 7446 looked like.
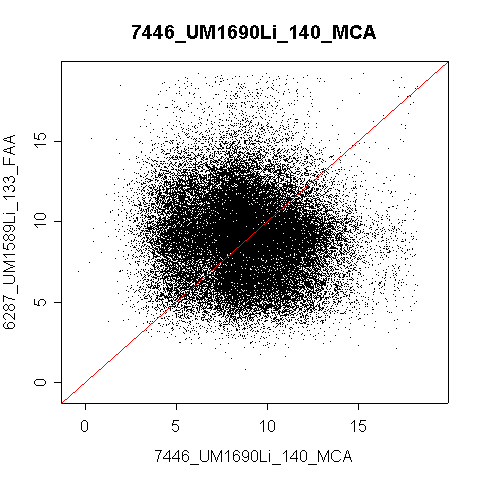
Compare this to 7446 versus 7447.
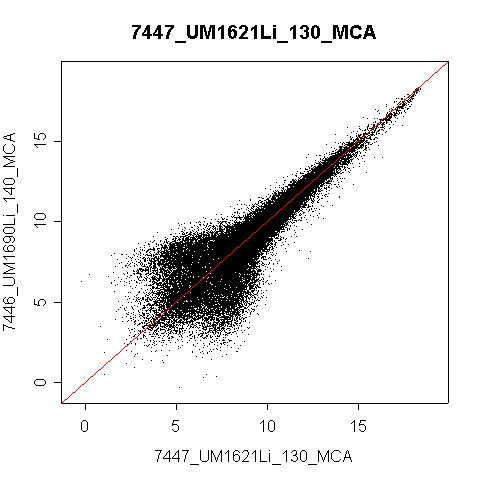
It turns out that the order of the genes were not the same in all of the files. For example in file 6287, the first ten genes were
- 1007_s_at
- 1053_at
- 117_at
- 121_at
- 1255_g_at
- 1294_at
- 1316_at
- 1320_at
- 1405_i_at
- 1431_at
while in file 7446, the first ten genes were
- 117_at
- 121_at
- 177_at
- 179_at
- 320_at
- 336_at
- 564_at
- 632_at
- 823_at
- 1053_at
By assuming that all the files listed their genes in the exact same order, I had effectively shuffled the values of three of the arrays and thereby ruined any analyses. To fix this, I had to sort the CSV files to insure that the gene names were in the same order for each file. Then I added a couple of extra lines of code to double-check that the files were now in a consistent order. Details of the code are in Stats: Importing data from a microarray experiment.
I should have been more careful at the beginning, but at least I caught the problem before I ran any serious analyses. Whew!
The big lesson learned here is to always check things as you go along. Sometimes an obvious assumption about your data may be mistaken.
You can find an earlier version of this page on my original website.