I got a question about the Bayesian model for rejection/refusal rates. I had used three prior distributions in my calculations, a Beta(10,40), a Beta(45,5), and a Beta(25,25). The question was, how did I select those prior distributions.
The honest answer is that I just made up some values. This was an early attempt to develop a Bayesian model for rejection/refusal rates, and the data for the project was already completed. I just wanted to show how it might work if you were starting a new trial.
The sum of the two parameters in the Beta distribution was 50 in all three cases. That was not a coincidence. I was trying to reflect a situation where the researcher had a moderate amount of information prior to the start of the study on how he/she believed that the rates would behave.
In a real setting, how would you arrive at 50 representing a moderate amount of prior information? There are many ways to do this, and it may make sense to use several approaches with one approach serving as a cross check for another.
The first approach, similar to an approach we used for monitoring exponential waiting times in a clinical trial, is to ask two questions.
- What is your best guess at the rate of success at this screening step?
- On a scale of 1-10, how confident are you about this value?
Call the answer to the first question s. Divide the answer to the second question by 10 to get P. Let n is the number of people you expect to screen at this step during the course of the trial. Then set your prior sample size (A+B) equal to nP. Set the ratio A/(A+B) equal to s. Solve for A and B. The solution is snP and (1-s)nP for A and B, respectively.
Here’s an example of this approach. Suppose the researcher was expecting the rate to be 20% and gave 3 as the level of confidence. The number of patients expected to reach this screening step is 2070. The prior sample size would be 0.3*2070 = 621. The values for A and B would be 124.2 and 496.8. There would be no harm in rounding these values a bit so A=125 and B=500 would represent the prior distribution.
A prior sample size of over 600 seems a bit big to me, and it may be worthwhile to look at this a different way.
A second approach is to ask the researcher to specify a best guess for the success rate and a worst case scenario success rate. Find a Beta distribution where the mean (or median) equals the best case and where a small percentile (e.g. 5th percentile) equals the worst case scenario.
Example: The researcher specifies a 20% success rate and suggests that a 10% success rate is the worst case scenario. Since computers are so fast, a brute force search across prior sample sizes from 1 to 600 works well.
worst.case <- rep(NA,600) for (i in 1:600) { worst.case[i] <- qbeta(0.025,0.2*i,0.8*i) }
A prior sample size of 48 comes closest to matching the worst case scenario. It is reasonable to round this value up to 50, which produces a Beta(10,40) prior distribution. For the sake of comparison, a prior sample size of 600 would produce 17% as the the 2.5 percentile.
A third approach is to use variation in previous studies success rates to estimate the prior distribution. It is often difficult to get such data, and the previous studies will always be at least a bit different if not a lot different from the current study under consideration. Nevertheless, if previous studies have success rates ranging from 5% to 40%, it makes no sense to choose a prior distribution where 95% of the probability lies between 17% and 23%.
A simple way to fit a Beta distribution to a sample from that distribution is the method of moments. The formula for the prior sample size for this Beta distribution is simply
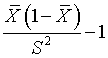
Example: Suppose that the success rates
0.19 0.22 0.33 0.17 0.24 0.24 0.25 0.25 0.18 0.31
The average of these ten studies is 0.2 and the variance is 0.0027. Using the method of moments, you compute a prior sample size of approximately 60. This indicates that a Beta(12,48) is a reasonable choice for the prior distribution.
Since two approaches produced a prior sample sizes of 50 and 60, the other prior sample size of 600 looks perhaps to be a bit too precise. The process of eliciting an informative prior distribution will benefit by looking at a range of different approaches. You should use one approach to refine or revise the prior distribution produced by a different approach.
There are more methods for eliciting a reasonable prior distribution than the three shown here. One issue that remains, however, is when researchers make mistakes in specifying a prior distribution, they tend to produce priors with too great a degree of certainty. Perhaps a system for eliciting prior distributions should automatically downweight the prior distribution that a researcher specifies. This is an area that warrants further examination.
You can find an earlier version of this page on my original website.