When I was young and naive, I thought that anytime you encountered ordinal data, it would make the most sense to use a test statistic based on ranks, such as the Mann-Whitney-Wilcoxon test or the Kruskal-Wallis test. Unfortunately, the ranks can sometime distort the true nature of an ordinal scale.
I thought that I had provided an example of how ranks can distort things, but I could not find it this morning when someone asked a question relating to ordinal scales. So here is the example again.
Suppose we ask in a survey about people’s income, but the question is asked in an ordinal fashion. For example:
What is your family’s gross annual income? a. 0-5,000 dollars b. 5,000-20,000 dollars c. 20,000-50,000 dollars d. 50,000-100,000 dollars e.100,000-250,000 dollars f. more than 250,000 dollars
You get 50 responses and they are summarized below
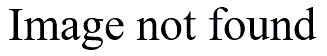
Now what happens if you try to rank this data? The 11 people in the lowest category would have ranks 1-11. The commonly used approach would be to assign each of these 11 people a rank of 6, which represents the average of the ranks 1-11. Similarly the second category has ranks 12-24, and we assign an average rank of 18 to this group.
The table below shows the average rank computed for each of the 6 income categories.
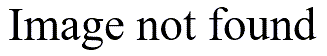
Notice that there is a relatively small shift in the average rank when you move from 50-100K to 100-250K. A shift of approximately 100,000 (subtracting the midpoints of these two categories) corresponds to a shift of only 6 units in the average rank. In contrast, a shift from 10-20K to 20-50K, a shift of approximately 20,000 has a shift of 12 units in the average rank.
So the net effect of this rank transformation is to make small changes in income seem relatively large and to make large changes in income seem relatively small.
There may be some particular applications where you do indeed want to put greater emphasis on changes in the lower income categories. For example, sometimes a small shift in income among relatively poor families has a larger impact than a large change among relatively rich families.
It’s perfectly fine if you make such a conscious decision to overemphasize small changes in income among relatively poor families. The problem is that the rank transformation will distort the scale without any active intervention or thought by you the researcher. The distortion will be based not on any property inherent in the categories themselves but solely in how frequently the different categories are populated.